In last post about Are Extensions the beauty or the beast? I added a screenshot that showed a class implementing the repository pattern. This actually also showed the implementation of our log strategy. I did get some questions why we do it like this and what are the benefits. Let’s have a look onto how we do it:
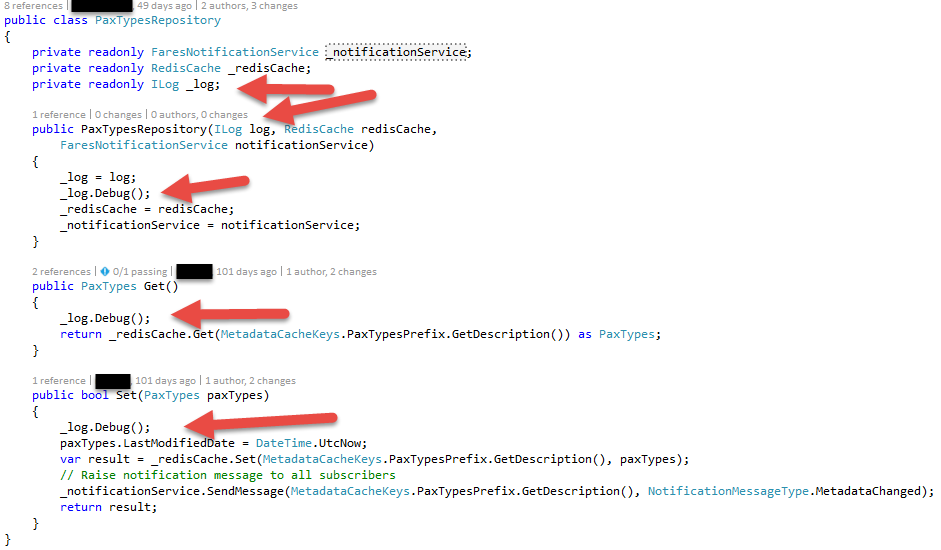
A log can be introduced as a service via dependency injection. It will be stored in an readonly variable and used (mostly) used in every public method.
What are the objectives of that procedure?
- The most important points are: Simplicity and uniformity.
- It shall be very easy to introduce a log to a class
- It shall be hurdle-free to add log messages that just push the name of the method to log. This shall include the name of the class.
- Log levels are available to distinguish information from fatal errors, from verbose messages
- Logging should be in best case identical in all classes, and even products and projects.
- The log shall produce a complete call stack/ execution path of the program, containing at least every public method
How do we accomplish that?
We do use dependency injection with Windsor Castle. Castle is a pretty mature framework that is on one hand very stable, robust and reliable and on the other hand, it is quite flexible and feature rich. If you don’t use dependency injection but used log4net, you may like the simplicity using the logging here.
- Logging follows log4net interface. This mainly has multiple methods per log level. E.g. Debug, DebugFormat, Info, InfoFormat and so on.
- five levels of logging are available: Debug, Info, Warn, Error, Fatal
- log4net expects to have one instance per class for logging. This sounds a little heavy but it does it also for simplicity. When logging information with log4net, it is not necessary to put information about time and which class logs that information. This is automatically done, which reduces the amount of information being added to the log information making the code more readible.. and shorter.
- While log4net expects a static variable and a hard reference to its Singleton, we did simplify it with dependency injection. Logging is just another service that can be introduced.
What is the result? Let’s have a look:
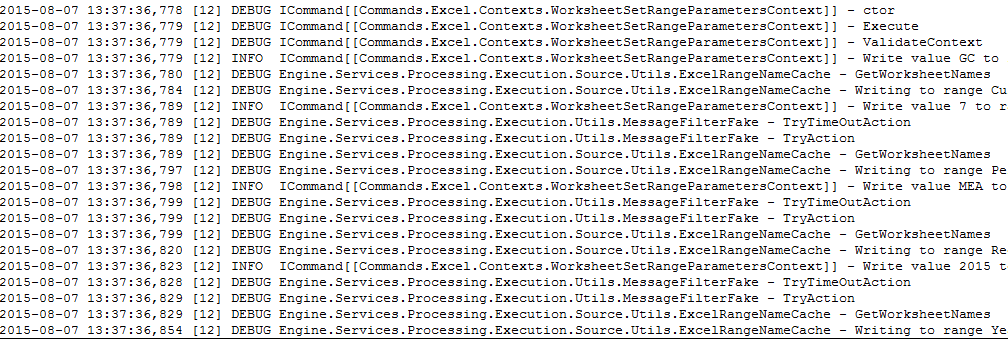
Please don’t take the namespace and the names of the classes in account – I needed to obfuscate them a little. As you can see, there are different log levels used, for sure. Datetime, thread and name of the actual class is available. The only thing the log method has to care about is after the hypen. This is actually the task of the code’s log messages to fill up with life.
What is visible right now is the complete execution path of the code. This particular piece is implemented with extensibility in mind. The base of the implementation is the command pattern where each command has its own context, defining the exact data for that command. For execution, commands are assembled, which can be cascading, and then executed. It is very easy to enhance this pattern as it is only necessary to implement another command and then change how commands are assembled.
To understand which commands have been executed, possibly in which context (see information about the particular worksheet that the WorksheetActiveLinkedPicturesCommand works on) it is just necessary to have a look onto the log. There are certainly better tools to visualize/ filter this log as this is the default log4net log which fileappender.
Mostly, I am satisfied with Notepad++. When it comes to multithreading issues, other tools and filtering do make sense.
Why this (extensive) logging? There are some good reasons – please consider these reasons to be valid when the software is in use by a customer. On the development machine, logging maybe is not that important as everything is in place and most probably, the developer has administrative permissions and can do whatever is necessary:
- On customer machines, debugging issues it hard to impossible depending on the IT department
- The more information is in place for a certain problem, the faster it is solved. Logging adds great load of information
- Debugging is time consuming. Creating the exact environment to reproduce a certain problem on customer site is much more. The more often it is possible to avoid that, the better it is.
- Debugging is pretty hard to impossible when having a multi-threading program
- Setting up the infrastructure and implementing this log functionality is pretty small effort. You may think this point is discussable. And it is.
What are the alternatives to that?
- Why not using AOP?
- We did try to use AOP but didn’t agree to the requirements. Either methods that shall be intercepted by AOP must be virtual or the class must be hidden behind an interface. Both strategies generated too much overhead from our point of view.
- Actual this is true for Windsor Castle, and is true for other frameworks. To be honest I don’t know if there are any outthere that are capable of minimizing the effort
- Is it mandatory to have that many logging methods?
- We agreed in the teams to have at least one logging method per public method.
- Catch blocks must log errors
- Additional information within methods are optional as logging parameters is
- Methods that are called so frequently that they pollute the log can be taken out
- Private/ internal methods may add logging when the developer expects them to add value
- Why not using debugging?
- Debugging is time consuming and problematic on customer machines. While there are tools available, a lot of customers don’t want to install anything for debugging purposes
- As stated debugging with program that use multiple threads is terrifying and often doesn’t lead to correct results
- Why not using a profiler? This is maybe available to the developer machine but most often it is not on customer site. Profilers can tell something about performance, but it has to issues.
- Due to calls are intercepted you may not generate the same issues in multithreading, you may create different or no.
- When it comes to misbehavior of code, information about in which order code has been executed is valueable
- Information about performance may be informative but not helpful depending on the actual problem
What are your strategies? Do you do logging?