The other day a collegue of mine came to me, being pretty enthusiastic. He was amazed about his latest changes to the code. As I am the responsible architect, it is my turn to have a look onto the changes. So we sat together and did so.
Usually we create our code via straight rules and best practices. As we use dependency injection, there are little to no statics in the code at least written by us.
Why?
Because statics are problematic when thinking about testability and maintainability. This is true especially when static classes maintain state.
There are reasons for statics but they are rare because usually they stand in the way. Let me shortly introduce you what we currently work on. I work with a collegue on a pretty complex Azure cloud solution, using cloud services. It keeps information about flight availabilities in a redis cache. This solution has some pretty hard constraints, let’s have a look onto that:
- It detects delta information via VPN on a customer SqlServer instance.
- Every single record will be pushed as a simple message via a service bus instance containing the information to be reloaded
- No single message is allowed to be lost. We have to keep consistency for 100%.
- Testability is a key. The system does >800 calls/s for keeping cache consistency and >2000 calls/s for reading out the cache. We are able to scale out, meaning we could do 10 times the load we have now. Seriously.
- We do have a test system deployed in the cloud, but it can tell the wrong story as it doesn’t have the same load, the same constraints as the productive one.
To keep a long story short, we need to have robust and reliable code. We follow SOLID, most of the rules we apply are identical to Clean Code. We create small classes and remove the necessity of thinking about dependencies.
So most of our classes look as simple as this:
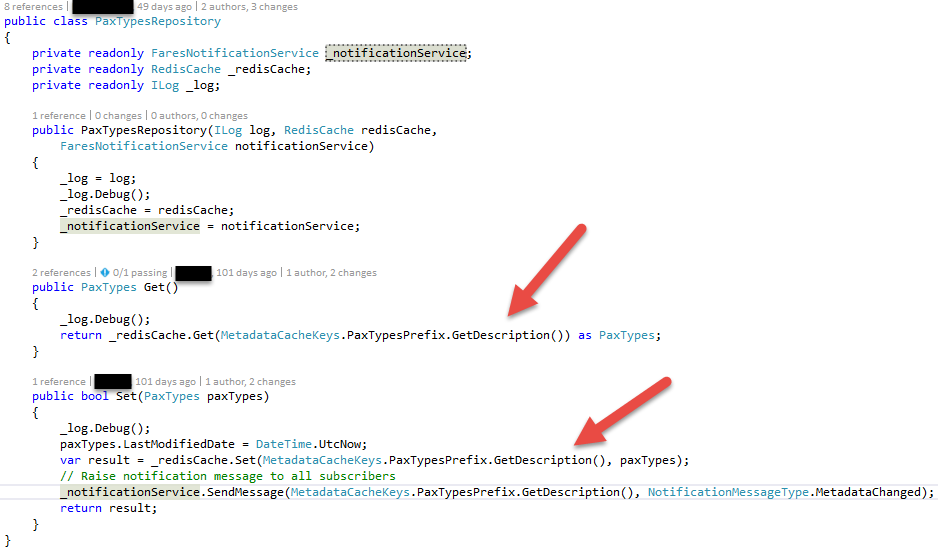
Some words about this class:
- I did break it down and changed it a little due to I am not allowed to post the original code
- The repository pattern should be recognizable. It doesn’t implement the full CRUD story, but Get & Set
- The classes rarely go over 50 lines of code
- Dependencies are injected, which means it is possible to focus on writing the code that is actually needed. This is important due to
- The developer is not forced to understand how a certain class is instantiated, thus he doesn’t need to have code in place to create it.
- This reduces code but also simplifies it, additionally reduces duplication, thus follows DRY.
- All repositories follow a straight pattern. If one has been understood, all are understood. This gains maintainability.
- Following Single Responsibility Principle,
- these small classes have only one reason to change. Changes doesn’t happen to often. Last change had been done ca. 100 days before
- When these classes are not touched, they’ll work. Certainly covered by automatic tests that prove that wanted functionality is covered.
- It is basically impossible to produce errors in such small classes. Once written, they work. It makes the developer fast.
- Enhancements are easy. The notification service has been added afterwards, as we recognized we need to push information over machine borders. It is as easy as inject another service and call it.
UPDATE:
I’ve got comments on this that the class actually doesn’t do too much, additionally having too much boilerplate code. Actually it is true. Most of the code stems from injecting services, while the actual doing is limited to use the RedisCache service – which implements all the magic necessary to work with a the actual RedisCache instance – and using the notification service. Why is it necessary to have it in I was asked? Let me explain:
All repository classes look like this. They are used in pretty much every place in the program where it is necessary to get information from a storage. There are two things at least that are important why we have this class in place:
- It is possible to recognize the pattern, thus people understand this procedure faster and getting used to the code faster.
- In the first run as stated we didn’t have the notification in place. We would have to introduce it somewhere else (maybe in the rediscache.set method). This would lead to have a lot of if statements as not all repositories need to notify. Having this in a single place is more obvious
- These classes are pretty small and don’t tend to be changed. That means a lot of small pieces that don’t change make the program more robust. Extensability is easy, maintainability and testability quite good.
Let me know your thoughts about, feel free to leave a comment.
Guess you’ve got the picture. Let’s now concentrate on Extensions.
We actually have exactly one here.
MetadataCacheKeys.PaxTypesPrefix.GetDescription()
The first time, I’ve seen it, I had to think about it. There is at least one that I don’t want to think about code: It is time. It should be as clear as possible. No stunts. No “intelligent” code. No “own style”. We need to do the same thing. All of us, meaning the whole team. If anyone does it how he likes it most, the others have to pay the price.
Let’s go into the details. What was the main point here? What had it looked like before?
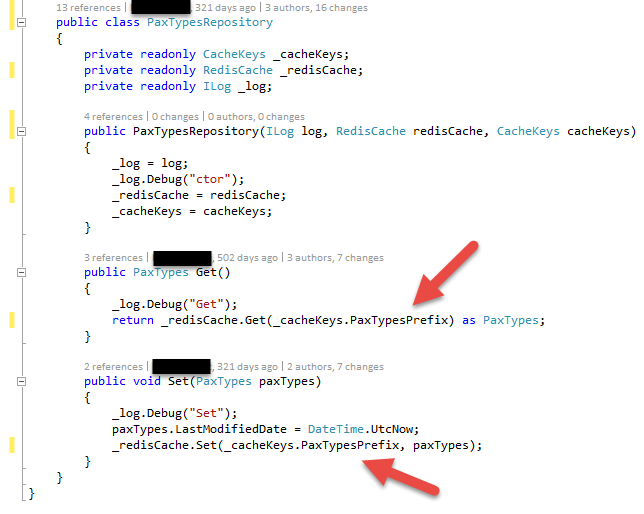
This was the code before. As you may recognize, notification wasn’t implemented 321 days before. Code evolves. The overall structure of this file stayed which is quite important for robustness. The reason for this class stayed, thus the code stayed comparable making the code maintainable, understandable and especially reliable.
One of the two most important lines is:
return _redisCache.Get(_cacheKeys.PaxTypesPrefix) as PaxTypes;
What do you consider to be more readible?
The previous version is more simple, for sure.
What was the reason to change it?
The old version was a service that just had properties containing the prefix information, looked like this:
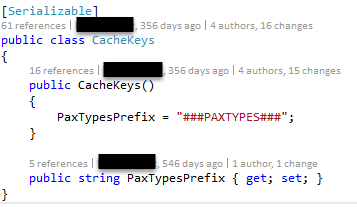
Actually keep in mind that I reduce the classes, certainly there was more than this prefix contained in that class. The point here was…it is some kind of cumbersome adding a new prefix because you need to define the content of the prefix in the ctor while having the property down there. That is the moment to think about these auto-property setter in C# 6.0. Back here it hasn’t been available.
UPDATE:
One of the comments I got had been that the actual CacheKeys class should never have been created due to the fact that in terms of encapsulation the key shall only exist in the repository class itself. I completely agree to this. The reason for the class was simple: Having an overview of all keys in one central place, nevertheless this breaks SRP. It is a tradeoff. What’s your opinion on that? Let me know in the comments.
The current class is an enum with attributes containing the key. Additionally it needs an extension class that reads out this attribute.
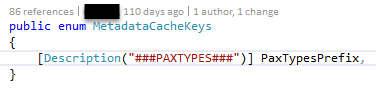
It is more handy but for the price
- of being more complex
- that it is necessary to think about it how it works in the first run (and what it is)
- that you need extensions for it
- that you need to know about this extension
- that you may feel this code is …avoidable?
Does that apply to all extensions? Let’s have a look onto other ones.
This is quite an extensive list. Let’s consider pro and cons:
Pro extensions:
- They are static, thus fast
- If they are atomic, they are testable
- They are handy, just in place when having the right using defined
Contra:
- Extensions lack architectural structure. “DataTableExtensions” can contain pretty much everything, from writing to disk to deleting columns in a datatable. That violates SRP – meaning it is problematic to keep track on what is available, how to extend and maintain.
As you can see, extensions are stored under a certain folder. We have extensions in place because they do make sense somewhen. But not as an architectural strategy. The following screenshot is the list of methods of DateTimeExtensions.
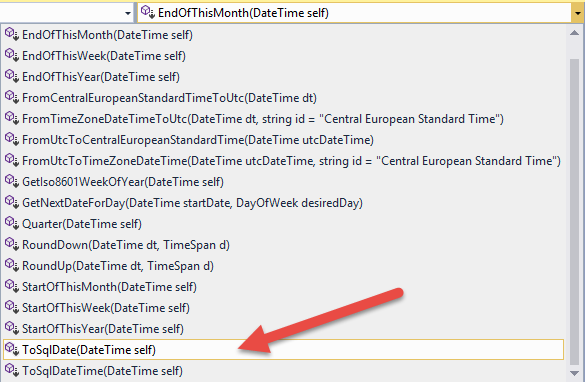
Do you see the ToSqlDate? Latest when this methods is added this class, things get mixed up.
Extensions invite the developer to just add something to classes because methods are more likely to fit because of the object they have been implemented for.
There are cases where extensions do make sense a lot. Considering linq, extensions do make totally sense. But not in every case, and not as a default solution for placing functionality. When using extensions, the feature should be generic, adoptable to all types of a certain class.
I do favor a good architecture over the ease of “just” putting my methods, though.