We recently went away from Azure Cloud Queue to migrate to Azure Service Bus. There had been a lot of reasons. One of the most important facts had been that we chosen Azure Cloud Queue due to performance. When we started decvelopment in a project with that technology middle of 2014, this was true.
Let’s say Microsoft didn’t put too much effort into Azure Cloud Queue, it rather put it into Azure Service Bus. So anyway we needed to move. Fast. As usual. Coding changes had been minimal. Anyway message processing is not coupled to the underlying transport mechanism (why should it?).
We did go, and the results had been pretty convincing:
- Much less usage of CPU power
- Much less usage of memory
- Faster processing of messages
- Message pump instead of polling messages (this is even cheaper!)
- Service Bus is much more feature rich
It worked pretty stable. For days, weeks, and months. We have 8 worker instances in place that maintain 12 processes doing requests against an ERP system. These processes do about 800 calls/s. This worked pretty stable, reliable for days, weeks, .. even months. After more than 30 days – we cannot say for sure because Stackify “only” let you go back for the maximum period of 30 days – the system didn’t do anything anymore. All processes (just to name it again: 96 different autark processes) on 8 workers stopped working in the same point in time.

The customer did recognize that problem after more than one day because data quality was pretty much reduced. There had been a lot of messages in service bus queue, about 1.5 million.
What did happen?
- Outage was not limited to one machine, or one process
- The system didn’t send any exceptions to Stackify. Not a single one.
- It worked like a charm for a pretty long period
- And all the workers had a problem in the same point in time.
That really smelled like an infrastructural problem on Azure side. We made it running again – restarting the workers had been sufficient. Opened a ticket at Microsoft to find out what was going on. While being in the process getting information from Microsoft, we had to make another deploy, which was a problem because when Microsoft was ready to look into the details, they had been removed by new workers instances. Pretty bad.
A little later, we’ve seen that there was a brand new nuget package for Service Bus. It fixed a problem that we may experienced:
Messaging: Fix a bug in all OnMessage pump api where a rare race condition can lead to ObjectDisposedException being thrown from the pump when processing callback takes too long.
Here we have a problem. We surely have a test systen, but it doesn’t have the same frequency in message processing… as it is a test system. And we would need to test at least for weeks to make this problem propably come up. We decided to upgrade to that package and deploy newly. So far so good. We would monitor the system and see if it works.
After some days the customer reported strange behavior. Processes are idle while are processes are running like hell. Normally each process does about 700 calls/ minute, now some of them do more than 2000 calls/ minute. One detail had been overlooked when deploying. Instead of 8 workers with 12 processes, we had 9 workers/ 12 processes. Due to the fact that it was suddenly more unpredictable how many messages a single process will work on in a certain time frame, it was problematic to calculate the overall count of messages per second.
This is an area where we cannot “just proceed”. When the system scales too high, the ERP system will get into trouble. It will be first slower, and – worst case – somewhen stop working. When we go over 2000 calls/s probably the latter will happen, and this will be costly. We are committed to do 800 calls/s. They don’t mind 1000 calls/s, when it is just a peak for a small time frame. We are not allowed to do this the whole day.
And again: What happened?

I had a look onto the metric we take for every single call we do against the ERP system. This is how the normal workload looks over a complete day.
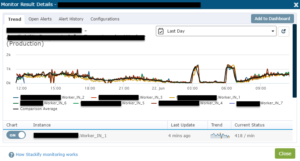
There are actually 7 workers running, working moreless identical and seamlessly. There are differences, but no outages. In the middle of the night, there are two peeks when the ERP system publishes a lot of changes that have to be worked on. Now to the problem:
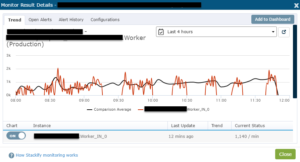
This is just one worker, showing time, where it processes much more messages than in the picture above, but with great outage times where it doesn’t do anything. How did this happen? We just changed the nuget package?
Let’s say, I wasn’t told a detail. The actual developer thought it would be time to let the processing of messages being more balanced. Actually, the current processing looks like this:
- Detecting the delta information what needs to be updated. This is information is made up of date, route, currency
- Gathering all delta information for certain routes, summarizing date and currency information
- Sending out “condensed” messages.
Why not just sending out message for every single information? We did do that before and realized, that a single worker even in multithreading cannot send that many messages in a sensible timeframe. Azure service bus allows sending maximal 500 messages/s. We didn’t plan to scale out with the component doing the detection as this has some technical issues. The delta detection should exactly be available once to prevent detecting a single delta multiple times. (I don’t take into account, they every component is at least available twice to be able to switch when workers are unexpectedly not available. In case of this worker we use a distributed mutex) Scale up would have been another possibility, but as sending messages does cost money, we decided for the cheapest and from the coding effort perspective fastest variant, just changing the information that is being transported.
These messages are sent to a Azure Worker Role that is called Controller. It retrieves all the messages from various sources and decides what to do with the message. Either an action is directly applied or the messages are resent, probably transformed.
In this case they had been resent without being transformed. And this was the change. Now they are transformed. But not in the controller anymore, as there are also only two instances. The worker instances actually used to process messages against the ERP system had been used to transform these messages to single messages only containing date, route and currency information. This lead to hundred thousands of messages.
It takes time to push hundred thousands of messages. And it takes time and effort to balance pushing these messages to the consumers.
So here we are: We have 96 autarc processes that split up messages and resend them to the service bus. The service bus queue has to maintain all the senders, beside the fact that the same 96 processes are also the listeners to that single queue. Here are the questions that have been not asked before changing the code and just deploy it.
- How long does it take to put all these messages on the Azure service bus queue?
- Are we faster with putting these messages than with processing these messages?
- How long does the Azure service bus queue needs to send out these message via message pump?
- Will the service bus be able to balance a huge amount of messages to this huge amount of listeners?
- What can we do to influence sending and retrieving messages? (read as: manipulate PrefechtCount, etc.)
As you can see in the diagram above, something doesn’t work like the developer expected it to. We went back with the changes which actually was just one file that changes had to be rejected. Afterwards, it worked fine again, like before. Although, condensed messages are not garantueed to be more reliable. The Azure infrastructure is not “just” working. It needs experience, and a lot of thoughts.
Never just deploy. Be aware of the consequences. Ask the right questions. Or love the risk and get into trouble 😉
Good post Holger! But if you never take a risk you will never know. 😉
Thanks Matjaz. There should be something in the middle, without “jumping in the chainsaw” 🙂