As stated in The natural border of azure cloud queue scalability we experienced pretty relevant issues with Cloud Queues.
We believed we solved the issues, though. As a result of too heavy usage of exactly one Storage Account, we devided to split the traffic – which actually really had too much to do – to several accounts to balance the work load. The original work load looked like this:
- Debugging information (azure diagnostics), mostly switched to mode “error” wich does not produce much load, but surely significant when switched to debug.
- 3 different cloud queues
- the most frequently used one has up to 200 messages per second used
- The other two are used to
- load meta data, which is one time a day, for actually ca. 1 hour pretty frequently used, adding additional ~50 messages per second
- backup a redis cache, which leads to additional messages as well as adding information to the blob storage
- Certainly every queue has a posion queue beside it to keep messages for that processing failed even in repetition. Good article about tha topic is Poison queues are a must!
- Blob storages
- one part of the game is exporting text files in csv format. These data of the files are prepared in sql azure tables, finally they are written to blob storage. Actually pretty much data, even when all that information is written as a zip stream.
- Table storage
- We count calls to ERP system that values are persisted in a table, which leads to call frequency of ~800 to ~1200 calls/s
- Other tracking/ monitor/ status information is kept in up to 5 different tables
Summarized, when thinking about the maximum ops of 20000/s that storage accounts are capable of – have a look in Azure storage scalability targets – is pretty much hit, when certain actions in the overall systems are running side by side.
The problematic thing here is, it is hardly predictable. The system ran fine for weeks and then broke. Anyway.
We split up the storage accounts and that helped a lot. The problem was solved, but we anyway had the plan to take the next step: Replace the cloud queue usage by service bus.
Certainly there are some constraints to be considered. There are actually a lot of differences in terms of usage, features and limitations between cloud queue and service bus. Have a look at Azure Queues and Service Bus queues – compared and contrasted to get the details.
We have some strong coding principles that help us to do this step. Actually, handling a message is not bound to the underlying queuing mechanism at all.
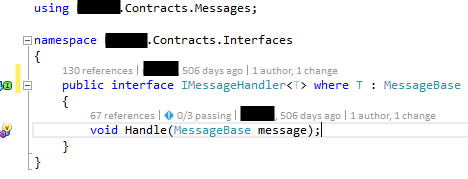
You can see, this interface didn’t change to much in the last months ;-). All the message handlers are based on this interface. Did you notice the issue in that interface? Shouldn’t it be like:
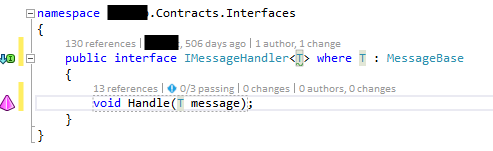
Yes, the T in the Handle message would be the straight way to go. No, we didn’t overlook this, it is a compromise. When doing dependency injection and defining the services like
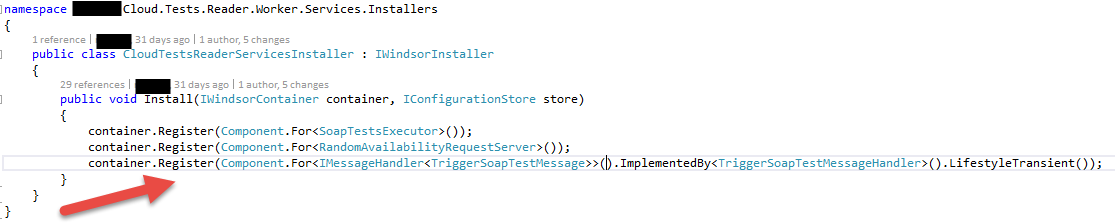
actually there would be no need to not define it as T. Using the MessageBase means the MessageHandler, that actually knows the type of message it will work on, has to cast once and do a parameter check before starting to work. That’s would be ugly, wouldn’t it?
The reason here is simple: When retrieving a message from service bus or cloud queue, we just have the message in place. Therefore we need to determine the type of the message and create a generic type that uses IMessageHandler plus the type of the message. Here we are in trouble. As we cannot know and don’t want to know the concrete type, we have to use the dynamic keyword.
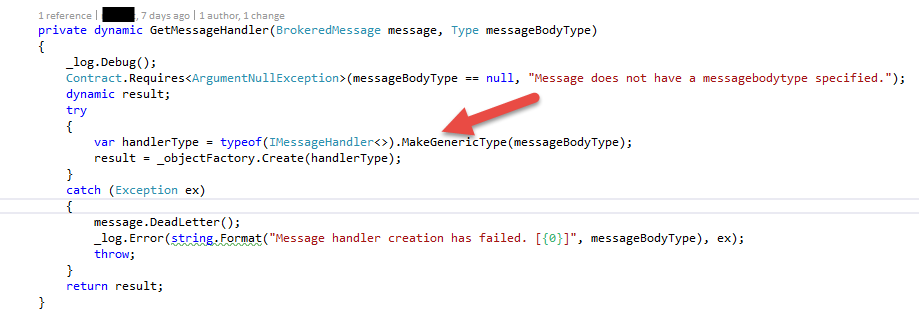
ObjectFactory here is an abstraction of ServiceLocator to not use the direct reference, thus making it better testable and maintainable. Nevertheless, as far as I know this is the only possibility to retrieve a generic type from the ServiceLocator via Windsor Castle – please comment if you know a better way! Would like to get rid of that glitch.
Nevertheless, in fact the message handlers are called with the data and work on that data, having no clue about who called them and how this message has been received, transported, etc.
This fact made it pretty simple to replace the cloud queue by Service Bus. The actual processing didn’t change at all. Due to the fact that Service Bus works quite different – Cloud Queue expects you to poll messages while Service Bus pushes messages, there was some kind of work to do to make it as robust as the available solution based on Cloud Queue.
What have been the results? Service Bus
- uses much less memory
- uses much less Cpu power
- remove the necessity of caring about frequency of polling messages. If there are any, you are going to be notified.
- is faster than Cloud Queue. We originally made the choice using the Cloud Queue over Service bus because of performance. 1 1/2 years before that was a fact. But since then, Service Bus is the favored messages technology of Microsoft, so Cloud queue didn’t move at all, or just a little while there is a lot of movement on Service Bus
Long story to get here, the moral of that story is certainly, the code really has to be prepared to change pretty much everything to keep track of movement we don’t have under control. Switching was a matter of days, including testing. We need to move fast. We did. Great.