Quite a while ago I was sitting together with another programmer to review the brand new sources. It was created as a prototype, a proof of concept. The original product has been rewritten for several reasons:
- The UI shall be completely redesigned
- The codebase had to be replaced due to bad maintainability and bad performance
Yes, certainly if there would have been proper abstractions of the logic there wouldn’t be the need to rewrite it from scratch. But in this case, from the business and the technical point of view it did make more sense to just drag out the logic how all that stuff had been done in the “old” version and create a new one completely rewritten.
Going through the code, I’ve seen these classes:
So there is a templates folder with classes that sound like models aka PONOs to me. Certainly being part of the review session, opened these files and was pretty surprised that there is a lot of functionality as well as data definition within these classes.
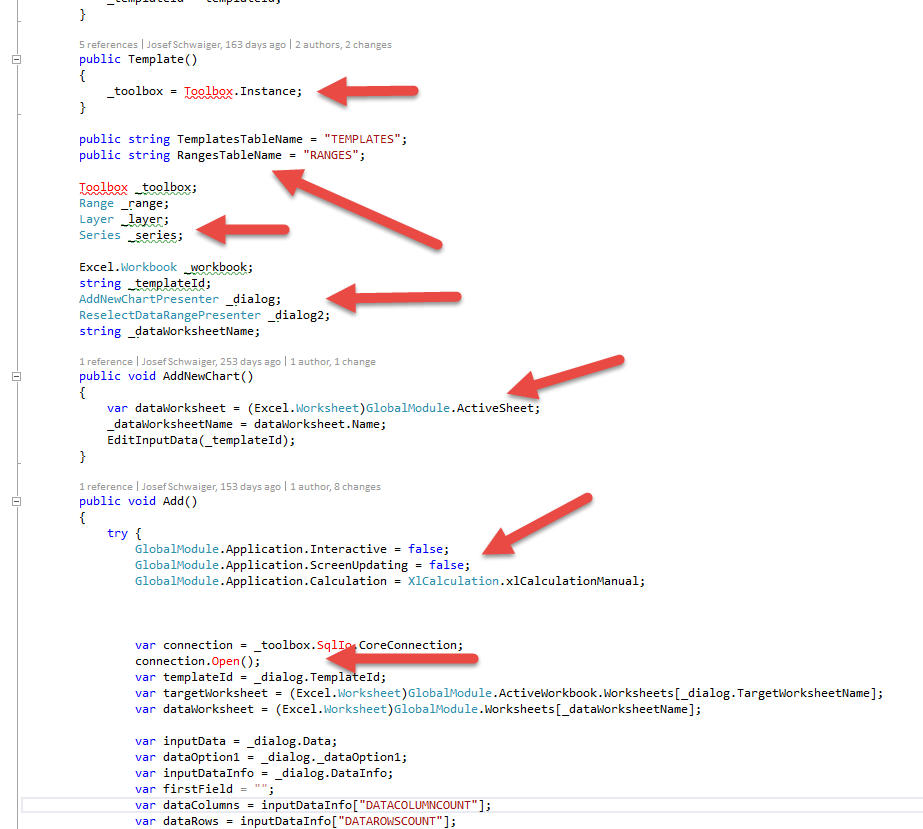
Yes, it didn’t compile on my machine, as you may recognize. Not that problematic as it anyway was rewritten completely. Anyway it wouldn’t have made me more happy because it would have been compilable :-D. I was missing some 3rdparty libraries like DevExpress.
So why it is heavy to find a name? This should be pretty obvious when watching this code. Most importantly – and hopefully not too surprising – the name of the class should be derived by its tasks.
- What does it do?
- Is it Single Responsibility or does the class have more than one task?
- Does it follow a best practice, so is a design pattern recognizable?
- Does it manage data/ does it hold state?
- Does it take decision or is it just a “worker”, a set of functions to be called?
Having a look onto that code base, the questions are not necessarily sensible. This class just does too much, takes decisions, opens connections, uses globals from Excel does some magic things with “constants” and dialogs.
It has a try catch block that catches my recognition. What can be done with that codebase to catch exceptions properly?

Okay, pretty frustrating. Just a finally, setting back some global variables for Excel.
What’s wrong with that beside the naming?
- Uses globals: Avoid that by introducing services that allow for changing behavior of environment
- Has no exception handling: Improper architecture often leads to problematic exception handling as the programmer doesn’t know how to handle all these problems that may arise. Separation of concerns/ Single responsibility is the key. When a class has only one tasks, it is pretty easy to find out what can go wrong and communicate that clearly to the caller.
- Uses magic strings and numbers: This is pretty problematic in various areas. These ranges that are referred to can change, so the code has to change. When at least one of these ranges is not available, the program will immediatly crash. The programmer doesn’t have any overview of what is already used and defined. So keep the naming of ranges straight forward and sensible is pretty hard to do when “just doing it”.You may be a genious, I am lazy. I don’t want to pollute my mind with names that I don’t want to remember in the middle of the night awaking ;-).
- No clear processing: What happens when? How to change the processing order? What is being accomplished? Why not separate single tasks in small methods and call them one by one to have an overview of actions being taken directly when entering the class?
- Connections: What happens when there is an network issue? When the connection had been opened and something else goes wrong? This is not even coding the happy case.
Stopping here, otherwise this is going to be a rant.
Just a final word about prototypes: I didn’t understand why most of the programmers start to program “quick and dirty” when the task is to create a prototype or a PoC.
Why is it a good idea to mess up every straight and well proven strategy when programming something that is subject to prove a certain thing?
Don’t tell me, you are faster. May be you put out some lines of code faster. But if there is no single thought about architecture, this is not going to be dirty, but just bad. These strategy never helps. I always, always apply the same strategies. This doesn’t take more time. It makes me faster.
And there is an additional benefit: The code is always reusable. So after the prototype, there is no need to start from scratch.